
前情提要
感觉做之前可以先看一下这个ppt,我是做了几道题之后才发现这个ppt的,里面提到的一些内容确实很关键rec04.pdf
题目
1
1
2
3
4
5
6
7
8
9
0000000000400ee0 <phase_1>:
400ee0: 48 83 ec 08 sub $0x8,%rsp
400ee4: be 00 24 40 00 mov $0x402400,%esi
400ee9: e8 4a 04 00 00 callq 401338 <strings_not_equal>
400eee: 85 c0 test %eax,%eax
400ef0: 74 05 je 400ef7 <phase_1+0x17>
400ef2: e8 43 05 00 00 callq 40143a <explode_bomb>
400ef7: 48 83 c4 08 add $0x8,%rsp
400efb: c3 retq
先看这个phase_1的代码。 这里的test 指令执行的是按位与(Bitwise AND)运算,但它不会保存运算结果,只会根据结果更新 CPU 的状态标志寄存器(EFLAGS)。也就是自己和自己按位与,这样能判断出来自己是非0,还有正负。应该就是trings_not_equal这里判别完之后返回的值放到这个寄存器了。 发现callq 401338
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
0000000000401338 <strings_not_equal>:
401338: 41 54 push %r12
40133a: 55 push %rbp
40133b: 53 push %rbx
40133c: 48 89 fb mov %rdi,%rbx
40133f: 48 89 f5 mov %rsi,%rbp
401342: e8 d4 ff ff ff callq 40131b <string_length>
401347: 41 89 c4 mov %eax,%r12d
40134a: 48 89 ef mov %rbp,%rdi
40134d: e8 c9 ff ff ff callq 40131b <string_length>
401352: ba 01 00 00 00 mov $0x1,%edx
401357: 41 39 c4 cmp %eax,%r12d
40135a: 75 3f jne 40139b <strings_not_equal+0x63>
40135c: 0f b6 03 movzbl (%rbx),%eax
40135f: 84 c0 test %al,%al
401361: 74 25 je 401388 <strings_not_equal+0x50>
401363: 3a 45 00 cmp 0x0(%rbp),%al
401366: 74 0a je 401372 <strings_not_equal+0x3a>
401368: eb 25 jmp 40138f <strings_not_equal+0x57>
40136a: 3a 45 00 cmp 0x0(%rbp),%al
40136d: 0f 1f 00 nopl (%rax)
401370: 75 24 jne 401396 <strings_not_equal+0x5e>
401372: 48 83 c3 01 add $0x1,%rbx
401376: 48 83 c5 01 add $0x1,%rbp
40137a: 0f b6 03 movzbl (%rbx),%eax
40137d: 84 c0 test %al,%al
40137f: 75 e9 jne 40136a <strings_not_equal+0x32>
401381: ba 00 00 00 00 mov $0x0,%edx
401386: eb 13 jmp 40139b <strings_not_equal+0x63>
401388: ba 00 00 00 00 mov $0x0,%edx
40138d: eb 0c jmp 40139b <strings_not_equal+0x63>
40138f: ba 01 00 00 00 mov $0x1,%edx
401394: eb 05 jmp 40139b <strings_not_equal+0x63>
401396: ba 01 00 00 00 mov $0x1,%edx
40139b: 89 d0 mov %edx,%eax
40139d: 5b pop %rbx
40139e: 5d pop %rbp
40139f: 41 5c pop %r12
4013a1: c3 retq
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
int strings_not_equal(char *strA, char *strB) {
// 1. 先比较长度
int lenA = string_length(strA);
int lenB = string_length(strB);
if (lenA != lenB) {
return 1; // 长度都不一样,肯定不相等
}
// 2. 长度一样,逐个字符比较
while (*strA != '\0') { // 只要还没读到字符串结束符
if (*strA != *strB) {
return 1; // 发现字符不一样,返回 1 (不相等)
}
strA++; // 指针后移
strB++;
}
// 3. 全比完了都没问题,那就是相等
return 0;
}
此时我有个问题,就是对于这种函数,参数是怎么传进来的,问了ai,发现这个问题就能直接搞完phase_1。主要就是有一个潜规则,调用函数之前,要把参数放到指定的寄存器,函数执行的时候去对应的寄存器取值,也就是%rdi和%rsi这两个寄存器,前者就是答案(详情查看附录1,附录1是ai的详细解释,不过有点错误,正确答案是rdi,自己输入的是rsi)。 后来发现这个课上有讲,我还没看到就先做这个题目了…
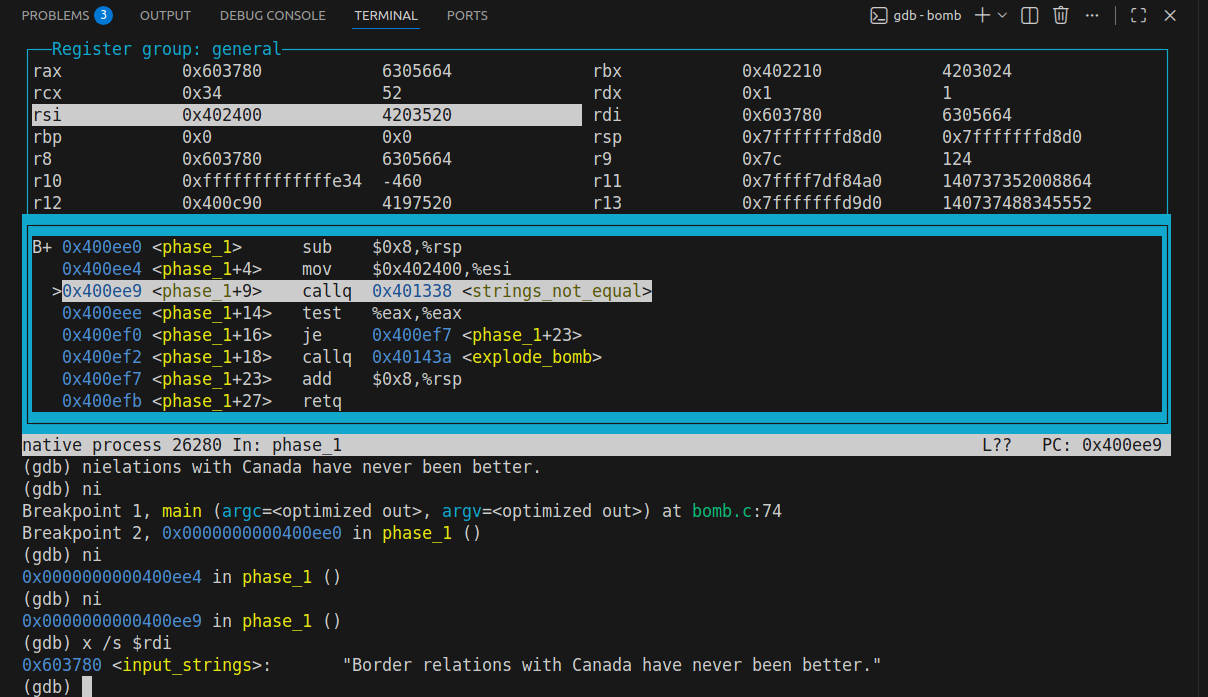
接下来可以debug,去查rdi的值了 流程:
启动 GDB。(gdb bomb)
layout asm + layout regs。(前者是打开汇编窗口,后者是查看所有寄存器)
break phase_1。(在这个函数的第一行打上断点)
run。(启动程序)
用 ni 一行行往下走,遇到 call 也可以 ni 越过。(ni是逐过程,si是逐语句)
用 x /s 偷看 %rdi 里的答案。(x /s $rdi 可以看到rdi这个寄存器所存指针对应字符串是什么)
然后就知道答案了“Border relations with Canada have never been better.”
2
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
0000000000400efc <phase_2>:
400efc: 55 push %rbp
400efd: 53 push %rbx
400efe: 48 83 ec 28 sub $0x28,%rsp
400f02: 48 89 e6 mov %rsp,%rsi
400f05: e8 52 05 00 00 callq 40145c <read_six_numbers>
400f0a: 83 3c 24 01 cmpl $0x1,(%rsp)
400f0e: 74 20 je 400f30 <phase_2+0x34>
400f10: e8 25 05 00 00 callq 40143a <explode_bomb>
400f15: eb 19 jmp 400f30 <phase_2+0x34>
400f17: 8b 43 fc mov -0x4(%rbx),%eax
400f1a: 01 c0 add %eax,%eax
400f1c: 39 03 cmp %eax,(%rbx)
400f1e: 74 05 je 400f25 <phase_2+0x29>
400f20: e8 15 05 00 00 callq 40143a <explode_bomb>
400f25: 48 83 c3 04 add $0x4,%rbx
400f29: 48 39 eb cmp %rbp,%rbx
400f2c: 75 e9 jne 400f17 <phase_2+0x1b>
400f2e: eb 0c jmp 400f3c <phase_2+0x40>
400f30: 48 8d 5c 24 04 lea 0x4(%rsp),%rbx
400f35: 48 8d 6c 24 18 lea 0x18(%rsp),%rbp
400f3a: eb db jmp 400f17 <phase_2+0x1b>
400f3c: 48 83 c4 28 add $0x28,%rsp
400f40: 5b pop %rbx
400f41: 5d pop %rbp
400f42: c3 retq
其实能把这段汇编翻译出来成C语言代码,这道题也就秒杀了。 Phase 2 的核心逻辑在于循环(Loop)和数组遍历。
入口特征:
callq read_six_numbers:明确了输入必须是 6 个整数。
sub $0x28, %rsp 和 mov %rsp, %rsi:说明这 6 个数字被存储在栈(Stack)上。
基准检查:
- cmpl $0x1, (%rsp):检查数组第 1 个数是否为 1。
循环体:
使用了两个指针:%rbx(当前遍历位置)和 %rbp(结束边界)。
核心运算:mov -0x4(%rbx), %eax 取出前一个数,add %eax, %eax 把它乘 2。
比较:cmp %eax, (%rbx) 检查当前数是否等于“前一个数 × 2”。 C语言代码: ```c void phase_2(char *input_string) { // 1. 在栈上开辟空间,读取输入 // 对应汇编: sub $0x28, %rsp; … call read_six_numbers int numbers[6]; read_six_numbers(input_string, numbers);
// 2. 检查第一个数 // 对应汇编: cmpl $0x1, (%rsp) if (numbers[0] != 1) { explode_bomb(); }
// 3. 循环检查剩余的数 // 对应汇编: lea 0x4(%rsp), %rbx (指向第2个数) // lea 0x18(%rsp), %rbp (指向末尾) int *current = &numbers[1]; int *end = &numbers[6];
do { int prev_val = *(current - 1); // 获取前一个数 (-0x4) int expected = prev_val * 2; // 期望值 = 前一个数 * 2 (add %eax, %eax)
1 2 3 4 5
if (*current != expected) { explode_bomb(); } current++; // 指针后移 (add $0x4, %rbx) } while (current != end);// 也就是等比数列: 1 2 4 8 16 32 } ```
在做这道题目的时候,有一系列的问题,就汇总到附录2里了。 答案是“1 2 4 8 16 32”
3
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
0000000000400f43 <phase_3>:
400f43: 48 83 ec 18 sub $0x18,%rsp
400f47: 48 8d 4c 24 0c lea 0xc(%rsp),%rcx
400f4c: 48 8d 54 24 08 lea 0x8(%rsp),%rdx
400f51: be cf 25 40 00 mov $0x4025cf,%esi
400f56: b8 00 00 00 00 mov $0x0,%eax
400f5b: e8 90 fc ff ff callq 400bf0 <__isoc99_sscanf@plt>
400f60: 83 f8 01 cmp $0x1,%eax
400f63: 7f 05 jg 400f6a <phase_3+0x27>
400f65: e8 d0 04 00 00 callq 40143a <explode_bomb>
400f6a: 83 7c 24 08 07 cmpl $0x7,0x8(%rsp)
400f6f: 77 3c ja 400fad <phase_3+0x6a>
400f71: 8b 44 24 08 mov 0x8(%rsp),%eax
400f75: ff 24 c5 70 24 40 00 jmpq *0x402470(,%rax,8)
400f7c: b8 cf 00 00 00 mov $0xcf,%eax
400f81: eb 3b jmp 400fbe <phase_3+0x7b>
400f83: b8 c3 02 00 00 mov $0x2c3,%eax
400f88: eb 34 jmp 400fbe <phase_3+0x7b>
400f8a: b8 00 01 00 00 mov $0x100,%eax
400f8f: eb 2d jmp 400fbe <phase_3+0x7b>
400f91: b8 85 01 00 00 mov $0x185,%eax
400f96: eb 26 jmp 400fbe <phase_3+0x7b>
400f98: b8 ce 00 00 00 mov $0xce,%eax
400f9d: eb 1f jmp 400fbe <phase_3+0x7b>
400f9f: b8 aa 02 00 00 mov $0x2aa,%eax
400fa4: eb 18 jmp 400fbe <phase_3+0x7b>
400fa6: b8 47 01 00 00 mov $0x147,%eax
400fab: eb 11 jmp 400fbe <phase_3+0x7b>
400fad: e8 88 04 00 00 callq 40143a <explode_bomb>
400fb2: b8 00 00 00 00 mov $0x0,%eax
400fb7: eb 05 jmp 400fbe <phase_3+0x7b>
400fb9: b8 37 01 00 00 mov $0x137,%eax
400fbe: 3b 44 24 0c cmp 0xc(%rsp),%eax
400fc2: 74 05 je 400fc9 <phase_3+0x86>
400fc4: e8 71 04 00 00 callq 40143a <explode_bomb>
400fc9: 48 83 c4 18 add $0x18,%rsp
400fcd: c3 retq
这道题目如果把汇编翻译成c语言的话,也就秒了……总感觉是不是不应该这么做呢…… phase_3 主要考察的是 C 语言中 switch 语句 的汇编实现,特别是跳转表 (Jump Table) 的使用。程序读取两个整数,第一个整数作为索引(Index),进入不同的分支,每个分支会给出一个预设的答案,最后校验你的第二个输入是否与该答案匹配。
- 跳转表地址:在汇编指令 jmpq *0x402470(,%rax,8) 中,0x402470 是跳转表的基地址。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
void phase_3(char *input) {
int num1, num2;
int target_value;
// 1. 调用 sscanf 解析输入。%eax 返回成功读取的个数。
// 汇编中:cmp $0x1, %eax; jg ... 表示必须读取 > 1 个参数
if (sscanf(input, "%d %d", &num1, &num2) <= 1) {
explode_bomb();
}
// 2. 边界检查。%num1 存放于 0x8(%rsp)
// 汇编中:cmpl $0x7, 0x8(%rsp); ja ... 表示 num1 必须 <= 7
if ((unsigned int)num1 > 7) {
explode_bomb();
}
// 3. 跳转表逻辑 (Switch-Case)
// 汇编中:jmpq *0x402470(,%rax,8)
// 根据 num1 的值跳转到对应的代码块
switch (num1) {
case 0: target_value = 207; break; // 0xcf
case 1: target_value = 707; break; // 0x2c3
case 2: target_value = 256; break; // 0x100
case 3: target_value = 389; break; // 0x185
case 4: target_value = 206; break; // 0xce
case 5: target_value = 682; break; // 0x2aa
case 6: target_value = 327; break; // 0x147
case 7: target_value = 311; break; // 0x137
}
// 4. 最终校验
if (num2 != target_value) {
explode_bomb();
}
}
4
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
000000000040100c <phase_4>:
40100c: 48 83 ec 18 sub $0x18,%rsp
401010: 48 8d 4c 24 0c lea 0xc(%rsp),%rcx
401015: 48 8d 54 24 08 lea 0x8(%rsp),%rdx
40101a: be cf 25 40 00 mov $0x4025cf,%esi
40101f: b8 00 00 00 00 mov $0x0,%eax
401024: e8 c7 fb ff ff callq 400bf0 <__isoc99_sscanf@plt>
401029: 83 f8 02 cmp $0x2,%eax
40102c: 75 07 jne 401035 <phase_4+0x29>
40102e: 83 7c 24 08 0e cmpl $0xe,0x8(%rsp)
401033: 76 05 jbe 40103a <phase_4+0x2e>
401035: e8 00 04 00 00 callq 40143a <explode_bomb>
40103a: ba 0e 00 00 00 mov $0xe,%edx
40103f: be 00 00 00 00 mov $0x0,%esi
401044: 8b 7c 24 08 mov 0x8(%rsp),%edi
401048: e8 81 ff ff ff callq 400fce <func4>
40104d: 85 c0 test %eax,%eax
40104f: 75 07 jne 401058 <phase_4+0x4c>
401051: 83 7c 24 0c 00 cmpl $0x0,0xc(%rsp)
401056: 74 05 je 40105d <phase_4+0x51>
401058: e8 dd 03 00 00 callq 40143a <explode_bomb>
40105d: 48 83 c4 18 add $0x18,%rsp
401061: c3 retq
0000000000400fce <func4>:
400fce: 48 83 ec 08 sub $0x8,%rsp
400fd2: 89 d0 mov %edx,%eax
400fd4: 29 f0 sub %esi,%eax
400fd6: 89 c1 mov %eax,%ecx
400fd8: c1 e9 1f shr $0x1f,%ecx
400fdb: 01 c8 add %ecx,%eax
400fdd: d1 f8 sar %eax
400fdf: 8d 0c 30 lea (%rax,%rsi,1),%ecx
400fe2: 39 f9 cmp %edi,%ecx
400fe4: 7e 0c jle 400ff2 <func4+0x24>
400fe6: 8d 51 ff lea -0x1(%rcx),%edx
400fe9: e8 e0 ff ff ff callq 400fce <func4>
400fee: 01 c0 add %eax,%eax
400ff0: eb 15 jmp 401007 <func4+0x39>
400ff2: b8 00 00 00 00 mov $0x0,%eax
400ff7: 39 f9 cmp %edi,%ecx
400ff9: 7d 0c jge 401007 <func4+0x39>
400ffb: 8d 71 01 lea 0x1(%rcx),%esi
400ffe: e8 cb ff ff ff callq 400fce <func4>
401003: 8d 44 00 01 lea 0x1(%rax,%rax,1),%eax
401007: 48 83 c4 08 add $0x8,%rsp
40100b: c3 retq
1. phase_4 逻辑分析
通过分析汇编,phase_4 的主要逻辑如下:
输入解析:使用 sscanf 读取两个整数(假设为 num1 和 num2)。
初步校验:
sscanf 的返回值必须为 2(即成功读取两个整数)。
num1 必须 ≤14(无符号比较)。
核心调用:调用 func4(num1, 0, 14)。
成功条件:
func4 的返回值必须等于 0。
num2 必须等于 0。
2. func4 C语言逻辑还原
func4 是一个经典的递归函数,实现的是二分查找算法。
codeC
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
int func4(int target, int low, int high) {
int mid = (high - low);
// 处理补码右移带来的正负号补偿 (汇编中的 shr 0x1f 和 add)
mid = (unsigned int)mid >> 31;
mid = (mid + (high - low)) / 2;
mid = mid + low;
if (mid > target) {
// 向左半区递归
return 2 * func4(target, low, mid - 1);
}
else if (mid < target) {
// 向右半区递归
return 2 * func4(target, mid + 1, high) + 1;
}
else {
// 找到目标值
return 0;
}
}
3. 确定最终答案
对于 num2:代码明确要求 cmpl $0x0, 0xc(%rsp) 且 je,所以 num2 = 0。
对于 num1:我们需要 func4(num1, 0, 14) == 0。
第一次计算 mid:(14 - 0) / 2 + 0 = 7。
如果 num1 == 7,函数直接返回 0。(解1)
如果 num1 < 7,向左递归,只要在后续路径中依然不触碰 mid < target 的分支(即不加 1),结果仍为 0。
测试路径:
7 -> 3 (mid=3, 如果 num1=3, 返回 0) (解2)
3 -> 1 (mid=1, 如果 num1=1, 返回 0) (解3)
1 -> 0 (mid=0, 如果 num1=0, 返回 0) (解4)
答案示例:7 0(或其他合法组合如 3 0, 1 0, 0 0)。
5
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
0000000000401062 <phase_5>:
401062: 53 push %rbx
401063: 48 83 ec 20 sub $0x20,%rsp
401067: 48 89 fb mov %rdi,%rbx
40106a: 64 48 8b 04 25 28 00 mov %fs:0x28,%rax
401071: 00 00
401073: 48 89 44 24 18 mov %rax,0x18(%rsp)
401078: 31 c0 xor %eax,%eax
40107a: e8 9c 02 00 00 callq 40131b <string_length>
40107f: 83 f8 06 cmp $0x6,%eax
401082: 74 4e je 4010d2 <phase_5+0x70>
401084: e8 b1 03 00 00 callq 40143a <explode_bomb>
401089: eb 47 jmp 4010d2 <phase_5+0x70>
40108b: 0f b6 0c 03 movzbl (%rbx,%rax,1),%ecx
40108f: 88 0c 24 mov %cl,(%rsp)
401092: 48 8b 14 24 mov (%rsp),%rdx
401096: 83 e2 0f and $0xf,%edx
401099: 0f b6 92 b0 24 40 00 movzbl 0x4024b0(%rdx),%edx
4010a0: 88 54 04 10 mov %dl,0x10(%rsp,%rax,1)
4010a4: 48 83 c0 01 add $0x1,%rax
4010a8: 48 83 f8 06 cmp $0x6,%rax
4010ac: 75 dd jne 40108b <phase_5+0x29>
4010ae: c6 44 24 16 00 movb $0x0,0x16(%rsp)
4010b3: be 5e 24 40 00 mov $0x40245e,%esi
4010b8: 48 8d 7c 24 10 lea 0x10(%rsp),%rdi
4010bd: e8 76 02 00 00 callq 401338 <strings_not_equal>
4010c2: 85 c0 test %eax,%eax
4010c4: 74 13 je 4010d9 <phase_5+0x77>
4010c6: e8 6f 03 00 00 callq 40143a <explode_bomb>
4010cb: 0f 1f 44 00 00 nopl 0x0(%rax,%rax,1)
4010d0: eb 07 jmp 4010d9 <phase_5+0x77>
4010d2: b8 00 00 00 00 mov $0x0,%eax
4010d7: eb b2 jmp 40108b <phase_5+0x29>
4010d9: 48 8b 44 24 18 mov 0x18(%rsp),%rax
4010de: 64 48 33 04 25 28 00 xor %fs:0x28,%rax
4010e5: 00 00
4010e7: 74 05 je 4010ee <phase_5+0x8c>
4010e9: e8 42 fa ff ff callq 400b30 <__stack_chk_fail@plt>
4010ee: 48 83 c4 20 add $0x20,%rsp
4010f2: 5b pop %rbx
4010f3: c3 retq
这道题,我没有让ai直接翻译了,自己逐行看了看。
- 这道题主要是考察数组
- 首先
40107f: 83 f8 06 cmp $0x6,%eax这行就是看输入字符串长度是不是6,也就是说答案是6个字符 - 等于6之后,会让rax从0开始遍历,直到5,一直有个循环,这个循环就是分别取出输入的6个字符,让每个字符和0xf做个and,得到的值作为新的索引去0x4024b0这个地址指向的字符数组去取新的值
- 0x4024b0这个地址指向的字符数组是”maduiersnfotvbylSo you think you can stop the bomb with ctrl-c, do you?”
- 然后取6次后得到一个字符数组,最后是要和$0x40245e指向的字符串做对比,这个地址的字符串是“flyers”
- “flyers”在”maduiersnfotvbylSo you think you can stop the bomb with ctrl-c, do you?”的索引分别是9、15、14、5、6、7
- 因为最后要和0xf做and,所以是可以加上个110000,也就是48,最后就是57、63、62、53、54、55,对应的字符就是“9?>567”
ai题解
Phase 5 的核心是一个基于“码表映射”的字符串变换算法。程序将你的输入作为索引,去一个预设的 16 字节字符表中查找对应的字符,最后拼接成一个新字符串进行比对。
1. C 语言伪代码还原
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
void phase_5(char* input) {
// 1. 长度检查:通常要求输入必须为 6 个字符
if (strlen(input) != 6) explode_bomb();
// 2. 预设资源
// 码表通常位于 $rbx 指向的内存,例如:"maduiersnfotvbyl"
char* lookup_table = "maduiersnfotvbyl";
// 目标字符串位于 0x40245e,例如:"flyers"
char* target_string = "flyers";
char result[7]; // 栈上开辟的空间 (0x10(%rsp))
// 3. 核心循环转换
for (int i = 0; i < 6; i++) {
// 取出输入字符的低 4 位(input[i] & 0x0F)
// 汇编对应:movzbl (%rbx, %rax, 1), %ecx
int index = input[i] & 0x0F;
result[i] = lookup_table[index];
}
// 4. 字符串收尾
// 汇编对应:movb $0x0, 0x16(%rsp)
result[6] = '\0';
// 5. 最终比对
if (strings_not_equal(result, target_string)) {
explode_bomb();
}
}
2. 解题步骤总结
定位目标:使用 x/s 0x40245e 找到程序想要的新字符串(如 ”flyers”)。
定位码表:查看 movzbl 附近的 %rbx 指针,找到 16 字节码表。
反向查表:
找到 ”flyers” 的每个字母在码表中的下标(Index)。
例如:若 ’f’ 在码表第 9 位,则你需要输入一个字符,其 ASCII 码的低 4 位为 9(如字符 ’i’,ASCII 0x69)。
构造输入:根据 6 个索引值,构造出对应的 6 个原始输入字符。
6
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
00000000004010f4 <phase_6>:
4010f4: 41 56 push %r14
4010f6: 41 55 push %r13
4010f8: 41 54 push %r12
4010fa: 55 push %rbp
4010fb: 53 push %rbx
4010fc: 48 83 ec 50 sub $0x50,%rsp
401100: 49 89 e5 mov %rsp,%r13
401103: 48 89 e6 mov %rsp,%rsi
401106: e8 51 03 00 00 callq 40145c <read_six_numbers>
40110b: 49 89 e6 mov %rsp,%r14
40110e: 41 bc 00 00 00 00 mov $0x0,%r12d
401114: 4c 89 ed mov %r13,%rbp
401117: 41 8b 45 00 mov 0x0(%r13),%eax
40111b: 83 e8 01 sub $0x1,%eax
40111e: 83 f8 05 cmp $0x5,%eax
401121: 76 05 jbe 401128 <phase_6+0x34>
401123: e8 12 03 00 00 callq 40143a <explode_bomb>
401128: 41 83 c4 01 add $0x1,%r12d
40112c: 41 83 fc 06 cmp $0x6,%r12d
401130: 74 21 je 401153 <phase_6+0x5f>
401132: 44 89 e3 mov %r12d,%ebx
401135: 48 63 c3 movslq %ebx,%rax
401138: 8b 04 84 mov (%rsp,%rax,4),%eax
40113b: 39 45 00 cmp %eax,0x0(%rbp)
40113e: 75 05 jne 401145 <phase_6+0x51>
401140: e8 f5 02 00 00 callq 40143a <explode_bomb>
401145: 83 c3 01 add $0x1,%ebx
401148: 83 fb 05 cmp $0x5,%ebx
40114b: 7e e8 jle 401135 <phase_6+0x41>
40114d: 49 83 c5 04 add $0x4,%r13
401151: eb c1 jmp 401114 <phase_6+0x20>
401153: 48 8d 74 24 18 lea 0x18(%rsp),%rsi
401158: 4c 89 f0 mov %r14,%rax
40115b: b9 07 00 00 00 mov $0x7,%ecx
401160: 89 ca mov %ecx,%edx
401162: 2b 10 sub (%rax),%edx
401164: 89 10 mov %edx,(%rax)
401166: 48 83 c0 04 add $0x4,%rax
40116a: 48 39 f0 cmp %rsi,%rax
40116d: 75 f1 jne 401160 <phase_6+0x6c>
40116f: be 00 00 00 00 mov $0x0,%esi
401174: eb 21 jmp 401197 <phase_6+0xa3>
401176: 48 8b 52 08 mov 0x8(%rdx),%rdx
40117a: 83 c0 01 add $0x1,%eax
40117d: 39 c8 cmp %ecx,%eax
40117f: 75 f5 jne 401176 <phase_6+0x82>
401181: eb 05 jmp 401188 <phase_6+0x94>
401183: ba d0 32 60 00 mov $0x6032d0,%edx
401188: 48 89 54 74 20 mov %rdx,0x20(%rsp,%rsi,2)
40118d: 48 83 c6 04 add $0x4,%rsi
401191: 48 83 fe 18 cmp $0x18,%rsi
401195: 74 14 je 4011ab <phase_6+0xb7>
401197: 8b 0c 34 mov (%rsp,%rsi,1),%ecx
40119a: 83 f9 01 cmp $0x1,%ecx
40119d: 7e e4 jle 401183 <phase_6+0x8f>
40119f: b8 01 00 00 00 mov $0x1,%eax
4011a4: ba d0 32 60 00 mov $0x6032d0,%edx
4011a9: eb cb jmp 401176 <phase_6+0x82>
4011ab: 48 8b 5c 24 20 mov 0x20(%rsp),%rbx
4011b0: 48 8d 44 24 28 lea 0x28(%rsp),%rax
4011b5: 48 8d 74 24 50 lea 0x50(%rsp),%rsi
4011ba: 48 89 d9 mov %rbx,%rcx
4011bd: 48 8b 10 mov (%rax),%rdx
4011c0: 48 89 51 08 mov %rdx,0x8(%rcx)
4011c4: 48 83 c0 08 add $0x8,%rax
4011c8: 48 39 f0 cmp %rsi,%rax
4011cb: 74 05 je 4011d2 <phase_6+0xde>
4011cd: 48 89 d1 mov %rdx,%rcx
4011d0: eb eb jmp 4011bd <phase_6+0xc9>
4011d2: 48 c7 42 08 00 00 00 movq $0x0,0x8(%rdx)
4011d9: 00
4011da: bd 05 00 00 00 mov $0x5,%ebp
4011df: 48 8b 43 08 mov 0x8(%rbx),%rax
4011e3: 8b 00 mov (%rax),%eax
4011e5: 39 03 cmp %eax,(%rbx)
4011e7: 7d 05 jge 4011ee <phase_6+0xfa>
4011e9: e8 4c 02 00 00 callq 40143a <explode_bomb>
4011ee: 48 8b 5b 08 mov 0x8(%rbx),%rbx
4011f2: 83 ed 01 sub $0x1,%ebp
4011f5: 75 e8 jne 4011df <phase_6+0xeb>
4011f7: 48 83 c4 50 add $0x50,%rsp
4011fb: 5b pop %rbx
4011fc: 5d pop %rbp
4011fd: 41 5c pop %r12
4011ff: 41 5d pop %r13
401201: 41 5e pop %r14
401203: c3 retq
这道题没用ai给我翻译,我直接一行一行地debug,看了好久,光草稿打了两页,用来记录各种值在干嘛,有点人肉翻译器了,这个逻辑本身不是很复杂,就是这寄存器换来换去的,还是高级语言看着顺啊….. 不想写的太详细了,哎,好麻烦,大概说下思路吧
- 这个题目时关于链表的,题目里有一个6个节点的链表,起始的顺序是:332->168->924->691->477->443
- 最后会对栈上的一个顺序去做比较,如果是个递减的顺序,就不会爆炸
- 首先,先读取输入的6个数字,其实也就是节点的顺序,存到栈里
- 然后会做一个运算,把上一步存到栈里的数字x,变成7-x
- 所以要存成4 3 2 1 6 5
- 然后会按这个顺序把节点存到栈里,最后在栈里做个顺序比较
![pZNOqHJ.jpg]()
![pZNObB4.jpg]()

ai题解
Phase 6 是二进制炸弹中最复杂的关卡,其本质是对单向链表进行重排序并验证顺序。
1. 核心数据结构
题目中定义了一个链表节点结构(16字节):
codeC
1
2
3
4
5
struct Node {
int value; // 节点数值(用于比较大小)
int id; // 节点编号 (1-6)
struct Node* next; // 指向下一个节点的指针
};
2. 逻辑分段解析(C语言翻译)
整个汇编过程可以拆解为四个核心步骤:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
void phase_6(char* input_str) {
int input[6];
read_six_numbers(input_str, input); // 读取6个数字
// --- 步骤 1: 检查输入合法性 ---
for (int i = 0; i < 6; i++) {
if (input[i] < 1 || input[i] > 6) explode_bomb();
for (int j = i + 1; j < 6; j++) {
if (input[i] == input[j]) explode_bomb(); // 不能重复
}
}
// --- 步骤 2: 关键变换 (7 - x) ---
// 汇编中有一个循环处理:val = 7 - val
for (int i = 0; i < 6; i++) {
input[i] = 7 - input[i];
}
// --- 步骤 3: 根据变换后的顺序重组链表 ---
// 汇编逻辑:
// 根据 input[i] 的值找到对应的 node 指针,并存入栈中的一个数组
Node* nodes[6];
for (int i = 0; i < 6; i++) {
Node* curr = &node1; // 链表起始地址
for (int j = 1; j < input[i]; j++) {
curr = curr->next;
}
nodes[i] = curr;
}
// 将选出的节点重新链接起来
for (int i = 0; i < 5; i++) {
nodes[i]->next = nodes[i+1];
}
nodes[5]->next = NULL;
// --- 步骤 4: 降序验证 ---
// 检查重组后的链表数值是否满足:node[i]->value >= node[i+1]->value
Node* test = nodes[0];
for (int i = 0; i < 5; i++) {
if (test->value < test->next->value) explode_bomb();
test = test->next;
}
}
3. 推导过程
观察原始数据(通过 x/2dw &node1 等命令):
- node1: 332, node2: 168, node3: 924, node4: 691, node5: 477, node6: 443
确定目标顺序(降序):
node3(924) > node4(691) > node5(477) > node6(443) > node1(332) > node2(168)
目标节点序列:3, 4, 5, 6, 1, 2
逆推输入值:
因为程序有 val = 7 - x 的逻辑,所以:
1
7−x=3⇒x=47−x=3⇒x=4
1
7−x=4⇒x=37−x=4⇒x=3
… 依此类推。
最终答案:4 3 2 1 6 5
附录
1
这是一个非常棒的问题!你触碰到了计算机系统中一个核心概念:ABI(Application Binary Interface,应用程序二进制接口) 和 调用约定(Calling Convention)。
你的猜测 “生成汇编的时候确认的” 其实非常接近真相。
1. 这是一个“君子协定”
你是对的,CPU 执行 callq 指令时,根本不知道有多少个参数,也不知道参数在哪里。CPU 只是傻傻地跳到了那个函数地址去执行代码。
能配合起来,全靠编译器遵守了一套严格的“潜规则”。在 Linux x86-64 系统下,这套规则叫 System V AMD64 ABI。
这就像送快递:
- 发送方(调用者):我知道规矩,先把第一个包裹放在“1号柜”,第二个放在“2号柜”……然后按门铃(call)。
- 接收方(被调用函数):我也知道规矩,听到门铃响了,我就直接去“1号柜”拿第一个包裹,去“2号柜”拿第二个。
如果有谁不遵守这个规矩(比如发送方把参数放在了错误的寄存器里),程序就会出错,得到乱码。
2. “六大金刚”:参数寄存器顺序
在 CS:APP (Linux x86-64) 环境中,前 6 个整数或指针类型的参数,必须按顺序存放在以下 6 个寄存器中:
| 参数序号 | 寄存器 | 助记(非官方) |
|---|---|---|
| 第 1 个参数 | %rdi | (DestIndex) |
| 第 2 个参数 | %rsi | (SourceIndex) |
| 第 3 个参数 | %rdx | (Data) |
| 第 4 个参数 | %rcx | (Counter) |
| 第 5 个参数 | %r8 | |
| 第 6 个参数 | %r9 |
注:如果有超过 6 个参数(很少见),剩下的会压入栈(Stack)里。
3. 举个栗子:从 C 到 汇编
假设 C 代码是这样的:
1
2
3
4
5
6
7
8
9
// 定义函数
long my_add(long a, long b) {
return a + b;
}
// 调用函数
int main() {
long sum = my_add(10, 20);
}
编译器在生成汇编时,会把代码翻译成这样:
在 main 函数(调用者)里:
编译器看到 my_add(10, 20),它心里想:“10 是第一个参数,20 是第二个。根据规矩,我得把它们放到 %rdi 和 %rsi。”
movq $10, %rdi ; 把 10 放入第一个参数柜子
movq $20, %rsi ; 把 20 放入第二个参数柜子
callq my_add ; 呼叫 my_add
在 my_add 函数(被调用者)里:
编译器生成 my_add 的代码时,它心里想:“我是被调用的,我要做 a+b。根据规矩,a 肯定在 %rdi 里,b 肯定在 %rsi 里。”
my_add:
movq %rdi, %rax ; 把 a (来自 %rdi) 放到 rax
addq %rsi, %rax ; 把 b (来自 %rsi) 加到 rax 上
retq ; 返回(结果通常放在 %rax 里)
你看,代码里并没有“告诉”函数参数在哪,而是双方都默认了位置。
4. 这对做 Bomb Lab 有什么用?
这个知识点是拆弹的关键!
当你在 phase_1 里看到这行代码时:
callq strings_not_equal
你立刻就能反应过来:
- 这是一个函数调用。
- 它一定需要参数。
- 根据“潜规则”,第 1 个参数在
%rdi,第 2 个参数在%rsi。
在 strings_not_equal 的语境下:
%rdi:通常是你输入的字符串(的地址)。%rsi:通常是正确的答案字符串(的地址)。
神级操作: 你只要在 GDB 里,在这个 callq 之前停下来,输入: x /s $rsi (意思:以字符串形式查看 %rsi 指向的内存)
砰! 答案就直接显示在屏幕上了。因为编译器必须把答案放在 %rsi 里传给比较函数。
总结
不是“生成汇编的时候确认的”,而是编译器被设计成必须遵守这套规则。
- 参数 1-6:
rdi,rsi,rdx,rcx,r8,r9。 - 返回值:
rax。
记住这几个寄存器,Bomb Lab 的难度会降低一半。
2
这一部分汇总了在调试过程中遇到的关于汇编语法、ABI 调用约定、PLT/GOT 机制以及GDB 调试的核心问题。
一、 汇编指令与基础概念
Q1: sub $0x28, %rsp 是什么意思?
- A: 这是在开辟栈空间。栈是向低地址生长的,减小栈指针 %rsp 等于在栈顶腾出新的空间(这里分配了 40 字节),用于存放局部变量(如本题中的 6 个整数)。
Q2: 为什么访问栈变量是 0x8(%rsp)(加法)而不是减法?
- A: 因为 %rsp 已经指向了栈的最底部(最低地址)。要在栈的范围内找数据,必须往地址增大的方向(向上)找,所以是加正偏移量。
Q3: test %eax, %eax 是在干什么?
- A: 这是在检查 %eax 是否为 0。通常用于检查函数返回值(如 strings_not_equal),如果返回 0(相等),ZF 标志位会被置 1,随后的 je 就会跳转。
Q4: 为什么 objdump 能看到 phase_1 这种函数名?
- A: 因为该程序在编译时没有被 Strip(剥离),保留了符号表(Symbol Table)。如果是商业软件,通常会被 strip 掉,只能看到内存地址。
二、 函数调用约定 (System V AMD64 ABI)
Q5: 汇编里调用函数怎么传递参数?
A: 依靠寄存器传递前 6 个参数,顺序为:
- %rdi 2. %rsi 3. %rdx 4. %rcx 5. %r8 6. %r9
- 返回值通常放在 %rax 中。
Q6: 为什么 read_six_numbers 调用时没看到设置 %rdi?
- A: 这是参数透传。父函数(phase_2)接收到的输入字符串就在 %rdi 里,它没改动过,直接顺手就把这个 %rdi 交给了子函数 read_six_numbers。
Q7: sscanf 调用前为什么要 mov $0, %eax?
- A: 对于可变参数函数(如 sscanf, printf),ABI 规定必须用 %al 告诉函数使用了多少个向量寄存器(XMM)传浮点数。因为这里没用浮点数,所以必须清零,否则可能导致未定义行为。
Q8: 为什么 sscanf 的指针参数在栈上要占 8 字节?
- A: 因为在 x86-64 架构下,所有指针(地址)都是 64 位(8字节)的。虽然 int 是 4 字节,但指向 int 的指针是 8 字节。
三、 PLT/GOT 与动态链接 (Lazy Binding)
Q9: call sscanf 时跳到的 jmpq *0x2xxx(%rip) 是什么?
A: 这是 PLT(过程链接表)。程序通过它实现延迟绑定。
RIP 相对寻址:offset(%rip) 算出的是 GOT(全局偏移表) 的地址。
%rip 是特殊的寄存器,专门放当前指令的地址
第一次运行:GOT 指向解析器,去寻找真正的函数地址并写回 GOT。
第二次运行:GOT 里已经是真地址,直接跳转,不再解析。
Q10: 为什么 PLT 里要 push ID 到栈上,而不是用寄存器传参?
- A: 为了避嫌(保护现场)。解析器运行需要征用寄存器,为了不破坏用户原本准备好的参数(如 %rdi, %rsi),PLT 只能把 ID 压栈,把脏活累活(保存/恢复寄存器)交给深层的解析器统一处理,这也就是下面说的解析器代码拥挤。
Q11: 为什么解析器代码比较“拥挤”反而是好事?
- A: 为了提高 CPU 缓存(Instruction Cache)命中率。PLT 表项做得很小(16字节),可以让一个缓存行(64字节)装下更多函数的跳转指令,减少 Cache Miss。
四、 调试坑点与技巧
Q12: 为什么 gdb bomb solution.txt 运行后 argc 还是 1?
A: 这种写法把文件名传给了 GDB 而不是程序。
正确做法:在 GDB 内输入 run solution.txt
或者启动gdb的时候用gdb -args bomb solution.txt
Q13: 为什么看内存时全是 0? (x /6d $rsi)
- A: 因为查看的时机不对。如果在 call 函数之前看,内存还未被写入。必须 ni 步过函数调用后,才能看到结果。
Q14: 为什么输入字符串明明一样,却爆炸了?
A: 两大元凶:
Windows 换行符:文件里有 \r\n,而 Linux 需要纯 \n。\r 会被当成字符读入导致不匹配。
缺少换行符:文件末尾如果没有回车,read_line 可能会把最后一个字符误当成换行符吃掉(例如吞掉句号)。
Q15: x /s 和 x /d 的区别?
A: x 是 Examine(检查内存)。
/s:戴着“字符串眼镜”看,遇到 \0 停止。
/d:戴着“十进制整数眼镜”看。
/x:戴着“十六进制眼镜”看(查隐形字符神器)。
Q16:TUI打开关闭快捷键?
- Ctrl-x a
- 这是为了开启/退出汇编布局
- layout src # 看源码窗口
- layout asm # 汇编布局
- layout split # 源码+汇编
- layout regs # 寄存器
3
Q1: 为什么变量存放在 0x8(%rsp) 而不是从 0(%rsp) 开始?
A: 这涉及栈对齐(Stack Alignment)和变量自然对齐。
ABI 规定:在调用函数(如 sscanf)前,%rsp 必须是 16 字节对齐的。
空间分配:编译器一次性开辟 0x18 (24字节) 空间。加上 call 压入的 8 字节返回地址,总开销为 32 字节(16的倍数),确保了后续调用的安全。
偏移选择:将变量放在 +8 的位置可以确保变量本身地址对齐,且在栈顶留下了一定的缓冲空间(Padding),提高了稳健性。
Q2: “返回地址”和“返回值”有什么区别?
A:
返回地址 (Return Address):是 call 指令执行时自动压入栈的(8 字节)。它是函数执行完后 ret 指令要跳转回去的“路标”。
返回值 (Return Value):是函数运算的结果,通常存放在 %rax 寄存器中。例如 sscanf 返回读到了几个数,这个数字在 %eax 里,而不在栈顶。
Q3: 为什么进入函数后 %rsp 指向的地址末尾通常是 8?
A: 因为在进入函数的第一行指令之前,CPU 执行了 call 指令,将 8 字节的返回地址压入了栈。如果进入前栈是对齐的(末尾为 0),那么压入 8 字节后,栈指针必然指向末尾为 8 的地址。所以函数第一句通常是 sub $…, %rsp,通过减去一个“末尾为 8”的数值(如 0x8, 0x18, 0x28)来重新实现 16 字节对齐。
Q4: 为什么调用 sscanf 前要执行 mov $0, %eax?
A: 这是 x86-64 调用约定对变长参数函数(如 printf, scanf)的要求。%eax 用于告知被调用函数“使用了多少个向量寄存器(XMM)来传递浮点参数”。因为本题只传递了整数地址,没有浮点数,所以必须清零 %eax,否则程序可能因试图访问不存在的浮点寄存器而崩溃。
Q5: GDB 调试时,x/w 和 x/g 的区别是什么?
A: 这是 GDB 中查看内存的单位:
w (word):代表 4 字节(针对 32 位历史遗留的定义)。
g (giant word):代表 8 字节(针对 64 位地址或长整型)。
注意:GDB 会记住你上一次使用的单位。如果想看 int 变量,请确保使用 w。
Q6: 为什么编译器不“边用边开辟”栈空间,而是一次性 sub 掉 24 字节?
A:
稳定性:一次性分配后,所有局部变量相对于 %rsp 的偏移量就固定了,方便指令寻址。
效率:减少 sub 指令的执行次数。
对齐:在函数开头一次性计算好对齐余量,比在代码中间动态维护 16 字节对齐要简单得多。
Q7: 这句汇编是什么意思jmpq *0x402470(,%rax,8)?
A:
这条指令 jmpq *0x402470(,%rax,8) 是 phase_3 的核心,也是汇编中实现 switch 语句 的最标准方式:间接跳转(Indirect Jump)。
为了让你彻底理解,我们把它拆解开来看:
1. 指令拆解
jmpq: 执行跳转。*(星号): 表示这是一个间接跳转。它不是跳转到0x402470这个地址,而是跳转到“存储在某个内存地址里的值”所指向的地方。0x402470(,%rax,8): 这是一个内存寻址表达式,公式是:目标内存地址 = 0x402470 + (%rax * 8)
2. 它是如何工作的?
想象内存里有一张表(Jump Table),起始地址是 0x402470。这张表里排排坐着一堆“目的地地址”。
%rax是索引:此时%rax里存的是你的第一个输入num1(比如 0, 1, 2…)。8是步长:在 64 位系统中,一个内存地址占 8 个字节。- 计算位置:
- 如果你输入
0:跳转到表里的第 0 项,即地址0x402470处存的那个目标。 - 如果你输入
1:跳转到表里的第 1 项,即地址0x402470 + 8处存的那个目标。 - 如果你输入
2:跳转到表里的第 2 项,即地址0x402470 + 16处存的那个目标。
- 如果你输入
- 最终一跳:CPU 从计算出来的内存位置取出那 8 个字节的内容(这内容本身也是个地址,比如
400f7c),然后直接跳过去。
3. 为什么要这样做?
如果不用跳转表,编译器得写一长串的 if-else:
1
2
3
4
if (x == 0) goto A;
else if (x == 1) goto B;
else if (x == 2) goto C;
...
这会导致 CPU 做大量的比较指令。而使用跳转表,无论你的 switch 有 10 个分支还是 100 个分支,CPU 只需要计算一次加法和乘法,就能一步到位跳转到对应的代码块,效率极高。
4. 调试技巧:如何看这张表?
既然你知道了基地址是 0x402470,你可以在 GDB 里直接把这张表打印出来看:
1
(gdb) x/8gx 0x402470
x: 检查内存(examine)。8: 显示 8 个单元(因为num1限制在 0-7)。g: 按巨字(Giant word,8字节)显示。x: 按十六进制显示。
你会看到类似这样的结果:
1
2
3
0x402470: 0x0000000000400f7c 0x0000000000400f83
0x402480: 0x0000000000400f8a 0x0000000000400f91
...
这些输出的地址(如 0x400f7c, 0x400f83)正对应着你汇编代码中处理各个 case 的起始位置!
总结
这行指令的意思就是:“请去内存 0x402470 开始的表格里,查一下第 %rax 项存的是哪个地址,然后跳到那个地址去。”
4
Q1: EFLAGS 寄存器显示 0x206 [ PF IF ] 是什么意思?
A: 这表示当前 CPU 的状态。PF(奇偶标志)和 IF(中断允许)被设为 1。由于方括号内没有 ZF (Zero Flag),说明上一次 cmp 或 test 的两个操作数不相等。
Q2: 为什么输入在 0-14 范围内还不够?
A: 0-14 只是初步范围限制。func4 的返回值取决于递归路径。由于右侧递归分支(mid < target)会给返回值加 1,而最终要求返回 0,所以你选择的数字必须保证在二分查找过程中永远不触发“向右转”的逻辑。
Q3: 为什么 (high - low) / 2 的汇编写得那么复杂?
A: 这是为了处理带符号整数除法。
- 矛盾点:C 语言要求除法“向零舍入”,而汇编的算术右移(
sar)是“向下舍入”。对于负数,这两者结果不同(例如-7 / 2应该是-3,但-7 >> 1会得到-4)。 - 解决办法:编译器采用
(x + bias) >> k的公式。对于除以 2 ($2^1$),如果 $x$ 是负数,就先给它加 1,再右移。 - 实现:通过
shr $0x1f提取符号位,正数得到 0,负数得到 1。将这个结果加到原数上,再进行右移,完美解决了正负数的舍入统一问题。
Q4: 为什么偏置值(Bias)是 $2^k - 1$,且这里 $k=1$?
A:
- $k=1$ 的原因:因为我们要计算的是
diff / 2。在二进制中,除以 $2^n$ 对应右移 $n$ 位。这里除以 $2^1$,所以 $k=1$。 - $2^k-1$ 的原因:这是数学证明的结果。当 $k=1$ 时,偏置值为 $2^1-1 = 1$。
- 对于负奇数(如 -7),加 1 变成 -6,右移 1 位得 -3(符合向零舍入)。
- 对于负偶数(如 -4),加 1 变成 -3,右移 1 位得 -2(结果不变,依然符合)。
- 对于正数,加 0,无影响。
Q5: lea (%rax,%rsi,1), %ecx 在这里起什么作用?
A: 虽然 lea 叫“加载有效地址”,但编译器常利用它做不带溢出检查的加法。这里它计算 rax + rsi(即 修正后的差值/2 + low),从而快速算出中间索引 mid。
Q6: shr $0x1f, %ecx 的深层含义是什么?
A: 这是一行极具代表性的位运算技巧。0x1f 是十进制的 31。将一个 32 位补码整数逻辑右移 31 位,会把该数的符号位移动到最低位,其余高位补 0。最终结果只有两种:
- 0(表示原数是正数);
- 1(表示原数是负数)。 编译器用这个技巧避免了使用昂贵的条件跳转指令(if/else)。
Q7: test %eax, %eax 后面跟着 jne 是在检查什么?
A: test 会对 %eax 自身做“与”运算。如果 %eax 为 0,ZF(零标志位)被设为 1;如果 %eax 不为 0,ZF 为 0。jne 是在 ZF=0 时跳转。因此,这两行合起来的意思是:“如果返回值不是 0,就去炸弹爆炸的分支”。
5
1. 寄存器与架构
Q: %fs:0x28 是什么意思?
- A: 它是 Stack Canary(栈金丝雀)。%fs 是段寄存器,指向线程局部存储(TLS)。程序在函数开头将该位置的一个随机数存入栈中,返回前检查是否被覆盖,以此防止栈溢出攻击。
Q: %cl、%ecx、%rcx 是什么关系?
- A: 它们是嵌套关系。%rcx 是 64 位,%ecx 是其低 32 位,%cl 是其低 8 位。修改 %ecx 会自动清零 %rcx 的高 32 位,但修改 %cl 则只影响最低字节。
Q: 除了通用寄存器,还有哪些特殊寄存器?
A:
%rip:指令指针,指向下一条指令。
%xmm 系列:128 位浮点/向量寄存器(MM 代表 Multi-Media)。
%rflags:状态标志位(如 ZF, CF)。
%dr0-%dr7:硬件调试寄存器,用于实现硬件断点。
2. 汇编指令细节
Q: 为什么 xor %eax, %eax 能清零?为什么不用 mov $0?
- A: 任何数异或自己结果为 0。xor 比 mov 更高效:机器码更短(2 字节 vs 5 字节),且 CPU 能在硬件层面识别此模式并实现“零延迟”清零,不占用运算单元。
Q: movzbl 指令的名字怎么读?
- A: mov-z-b-l:Move with Zero-extend Byte to Long。即将 8 位(字节)零扩展移动到 32 位(长字)寄存器中。
Q: movb $0x0, 0x16(%rsp) 中 b 和 0x16 的含义?
- A: b 代表操作 1 个字节。0x16 是十进制 22 的偏移量。这行代码通常用于在生成的字符串末尾手动添加 \0 结束符。
3. 机器码与断点原理
Q: 为什么 INT 3 断点的机器码是单字节 0xCC?
- A: 为了安全地替换任何长度的指令。如果断点是多字节的,替换时可能会覆盖下一条指令,导致多线程环境下其他 CPU 核心执行出错。单字节 0xCC 保证了断点插入的原子性。
Q: 软件断点和硬件断点的区别?
- A: 软件断点是通过修改代码为 0xCC 实现的,理论上无限多;硬件断点利用 DR 寄存器监控地址访问,数量有限(通常 4 个),但不需要修改代码,能监控“读/写”操作。
4. GDB 调试技巧
Q: 为什么打印出来的数字 49 会变成字符 ’1’?
- A: 因为计算机不区分数值和字符,只取决于你如何解读。49 的十六进制是 0x31,在 ASCII 码表中对应的就是字符 ’1’。使用 p/c 或 x/c 可以强制按字符显示。
Q: 如何在 GDB 中查看不同进制?
A:
二进制:p/t $rax (Two/Binary)
十六进制:p/x $rax (Hex)
十进制:p/d $rax (Decimal)
字符串:x/s <address>
Q: GDB TUI 模式下滚轮失效怎么办?
- A: 使用 focus cmd 命令将鼠标/键盘焦点切回命令行窗口;或者用 Ctrl+p/Ctrl+n 翻看命令历史。
Q: 进制表示法的前缀是什么?
- A: 十六进制用 0x,二进制用 0b,八进制用 0 或 0o。
6
第一波问题
第一部分:指令含义与数据转换
Q1: movslq %ebx, %rax 这行汇编是什么意思?
A: 这是一个带符号扩展移动指令。
拆解: MOV (移动) + S (Sign-extend, 符号扩展) + L (Long, 32位) + Q (Quadword, 64位)。
逻辑: 将 32 位的 %ebx 复制到 64 位的 %rax。如果 %ebx 是负数,高 32 位全补 1;如果是正数,全补 0。
用途: 通常用于将 int 类型的索引或变量提升为 long 类型,以便进行 64 位地址运算。
Q2: cmp %rsi, %rax 比较的是地址指向的内容吗?
A: 不是。 它比较的是寄存器里的值本身。
判断准则: 看有没有括号 ()。
cmp %rsi, %rax: 比较两个数值(比如 if (i == 6))。
cmp (%rsi), %rax: 才会把 %rsi 当地址,去比内存里的值(比如 if (*rsi == rax))。
第二部分:内存寻址与数据结构
Q3: mov (%rsp,%rax,4), %eax 是什么寻址方式?
A: 这是数组索引寻址。
公式: 地址 = %rsp + (%rax * 4)。
含义: %rsp 是数组首地址,%rax 是索引 i,4 是每个元素的大小(int 占 4 字节)。
场景: 这行代码通常是在从栈上读取你输入的第 i 个数字。
Q4: mov 0x8(%rdx), %rdx 是什么意思?是加 8 吗?
A: 不是加 8,而是链表跳转(Next 操作)。
逻辑: 去 rdx + 8 这个地址取 8 个字节的内容(即下一个节点的地址),然后存回 rdx。
C语言等效: rdx = rdx->next;
区分: add $0x8, %rdx 才是单纯的加 8(指针偏移)。
第三部分:GDB 调试陷阱与真相
Q5: 为什么查看内存时 x /d $edx+8 显示的是 -32,但执行 mov 后变成了地址或 -88?
A: 这是因为 GDB 显示格式与数据实际意义不符 造成的错觉。
地址碎片: 当你用 x/d(十进制)查看指针时,GDB 可能只读取了 1 个字节(如 0xe0)。在小端序中,如果一个地址是 0x…20e0,抓取 0xe0 并按有符号十进制解释,结果刚好是 -32。
执行前后差异: 执行 mov 0x8(%rdx), %rdx 前,你看到的是“存储在当前节点的 next 指针碎片”;执行后,rdx 已经跳到了新节点,你看到的是“新节点里的 value 成员”。
Q6: 为什么 mov %rdx, 0x20(%rsp,%rsi,2) 存入后,查看内存却显示 32?
A: 这又是一个十六进制与十进制的“巧合”。
原因: 你存入的是 %rdx 里的地址(假设地址是 0x603320)。
真相: 该地址的最后一个字节是 0x20。如果你查看内存的格式不对(比如只读了 1 字节),GDB 会把十六进制的 0x20 显示为十进制的 32。
结论: 这里搬运的是节点地址,而非节点数值。
第四部分:GDB 调试黄金法则 (技巧汇总)
看数值 (int): 使用 x /wd [地址] (Word, 十进制)。用于看节点存的数字。
看地址 (pointer): 使用 x /gx [地址] (Giant word, 十六进制)。用于看 next 指针和跳转目标。
确认执行: GDB 的箭头 => 指向的是即将执行但尚未执行的指令。看结果前一定要先执行一次 ni。
内存全貌: 怀疑数据不对时,用 x /2gx [地址] 同时看一个节点的“数值+ID”和“next指针”,这样最清楚。
补充问题(跑第二个上下文去了)
Q2: GDB 怎么给特定的汇编行打断点和删除?
打断点:break *0x4011xx (必须带星号)。
查看编号:info b。
删除:delete [编号]。
Q3: GDB 怎么跳过一个不想执行的循环?
跳转:jump *地址(直接修改 PC 指针,不执行中间代码)。
推进:advance *地址(运行到该地址处停止)。
手动改寄存器:set $rip = 0x4011xx。
Q4: 汇编中 lea 和 mov 的本质区别是什么?
lea 0x8(%rdx), %rsi:计算地址。相当于 rsi = rdx + 8。不访问内存。
mov 0x8(%rdx), %rsi:取值。相当于 rsi = *(rdx + 8)。访问内存。
Q5: 为什么 x $rdx+8 看到的是个奇奇怪怪的天文数字?
原因:GDB 默认的显示格式或单位(Unit Size)不对。如果它把 4 字节的 Value 和 4 字节的 ID 拼在一起按 8 字节十进制显示,就会出现巨大的无意义数字。
对策:明确指定格式。
x/gx:查看 8 字节十六进制(看指针)。
x/dw:查看 4 字节十进制(看整数)。
x/2dw:连续看两个 4 字节十进制。
Q6: 为什么执行了 mov %rdx, (地址) 后内存里的值没变?
原因 1:GDB 显示的是即将执行的那行。此时指令还没跑,需要再点一次 ni。
原因 2:rdx 里的值正好和内存里原有的值一样。
原因 3:查看的内存宽度不匹配,没注意到低位/高位的变化。
Q7: 怎么看“指针的指针”指向的内容?
在 GDB 中可以使用 C 风格转换:
- x/dw (long)($rdx + 8):取 $rdx+8 处存的地址,然后看那个地址里的十进制数值。